The most accurate AIin existence.
If you need answers you can trust, research-grade accuracy, or zero tolerance for hallucinations—Sup AI is your only option. We lead the world's hardest benchmark by 14+ percentage points.
HLE Accuracy (SOTA)
Lead vs Next Best
Built Different
Every feature you need.
Nothing you don't.
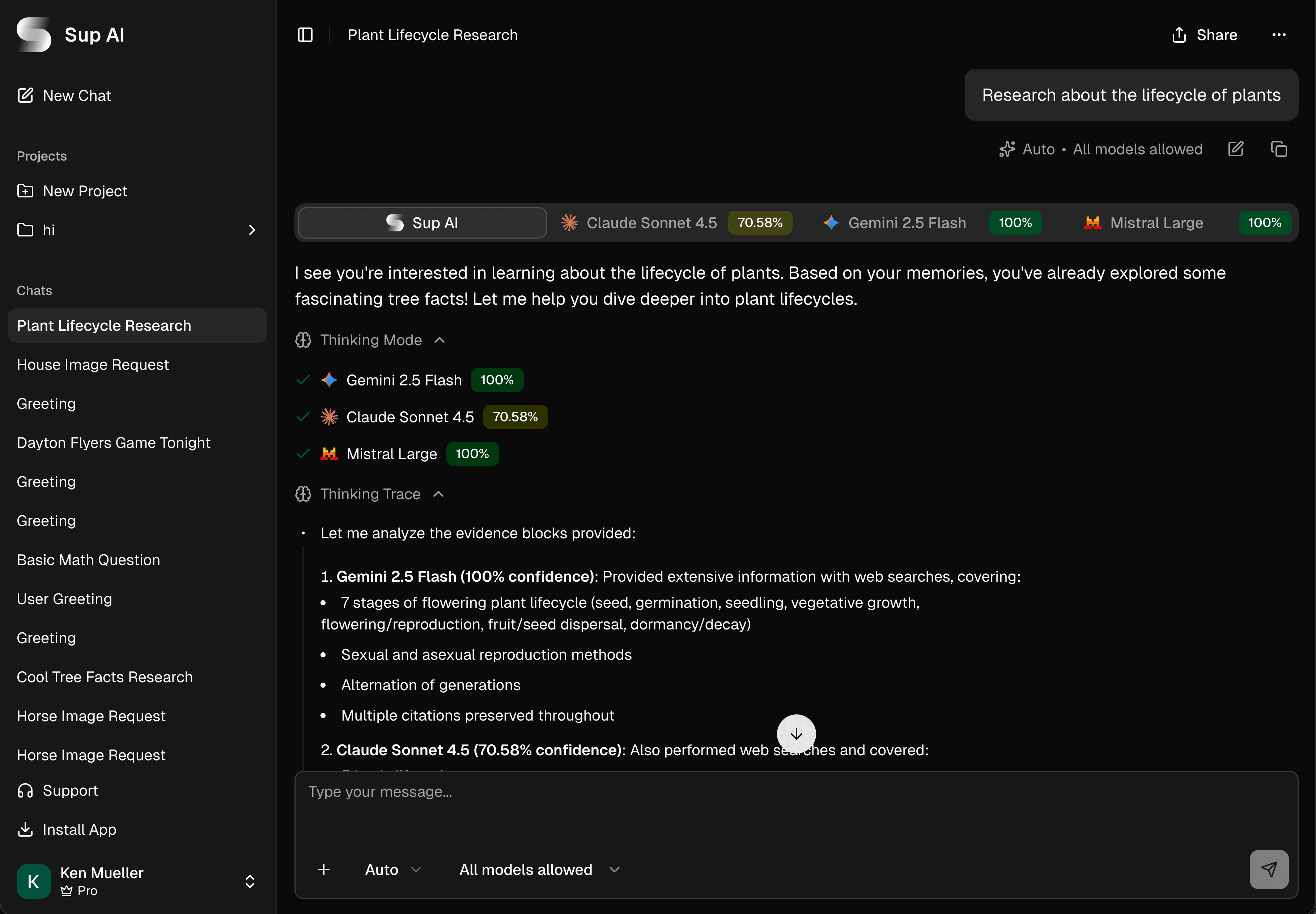
Multi-Model Orchestration
We intelligently route your queries to the best frontier models, combining their strengths for superior results.
Logprob Confidence Scoring
We analyze logprobs in real-time to measure confidence. Low-confidence responses are retried, and only high-confidence chunks make the cut.
Always Cited
Every claim backed by verifiable sources with inline citations you can click to verify.
Perfect Memory
Best-in-class multimodal RAG. Everything becomes permanent knowledge. Your AI never forgets anything.
Create and edit images
Weave images into your conversation with natural language commands. Images are embedded in context just like text, creating a truly multimodal conversation experience that other platforms simply cannot match.
State of the Art
52.15% on Humanity's Last Exam
+14.63% ahead of the next best model. Our ensemble orchestration unlocks capabilities beyond what any single model achieves alone.
Ensemble systems exceed individual model capabilities. We analyze logprobs to measure confidence in real-time. Low-confidence responses are automatically retried, and only high-confidence chunks from each model make it into the final answer.
Results are fully reproducible with complete traces →
Proven Accuracy
The new leader on the world's
most challenging AI benchmark
Humanity's Last Exam (HLE) is 3,000 questions across 100+ subjects, created by 1,000+ domain experts. It's designed to remain difficult as AI advances. Our results are fully reproducible with complete traces.
Accuracy comparison
Sup AI achieves 52.15% accuracy — 14+ percentage points ahead of the next best model (p<0.001).
If you need accurate answers, fewer hallucinations, or research-grade work that must be correct—Sup AI is your only option.
Disclaimer: These results are from an independent evaluation conducted by Sup AI (Dec 2025) and are not officially endorsed by the Center for AI Safety or Scale AI. Accuracy scores were calculated on a random sample of 1,369 questions from Humanity's Last Exam. All models, including competitors, were evaluated using enhanced settings (custom instructions, web search, and low-confidence retries) to maximize performance. Comparisons reflect model versions available at the time of testing, including "Preview" builds which are subject to change.
Capabilities
Built to eliminate hallucinations
Every feature engineered to maximize accuracy and deliver research-grade results. When correctness matters, there is no alternative.
Logprob Confidence Scoring
We analyze logprobs in real-time to measure confidence. Low-confidence responses are retried automatically, and only high-confidence chunks make it into the final answer.
Multimodal RAG
Upload images, PDFs, or documents and they become permanent knowledge. Your AI remembers everything, forever.
Intelligent Model Selection
Our orchestration layer analyzes your query and automatically selects the optimal frontier models for the task.
Secure Collaboration
Share projects without leaking personal data. Collaborate on chats with real-time editing and shared context.
Always Cited
Every claim backed by verifiable sources. We show you exactly where answers came from with inline citations.
Extended Thinking
Watch as models reason through complex problems step by step, showing their work with transparent thinking traces.
HLE accuracy (SOTA)
Lead vs next best
Source citations
Model Ecosystem
Every frontier model.
One intelligent layer.
We don't pick sides. We intelligently orchestrate the best models from every lab to deliver superior results.
GPT-5 Pro
OpenAI
Claude Opus 4.5
Anthropic
Claude Sonnet 4.5
Anthropic
Gemini 3 Pro Preview
Gemini 3 Pro Image (Nano Banana Pro)
Kimi K2 Thinking Turbo
MoonshotAI
DeepSeek V3.2 Exp
DeepSeek
Qwen3 Max
Alibaba
How It Works
Intelligent orchestration
Analyze
We analyze your query's complexity, domain, and requirements.
Select
We pick the optimal models for your task, balancing capabilities & speed.
Verify
We analyze logprobs in real-time to measure confidence. Low-confidence responses are automatically retried.
Deliver
We synthesize only high-confidence chunks from each model, weighted by confidence scores. Uncertainties are surfaced, never hidden.
Pricing
Simple pricing
Start for free. Upgrade when you need more.
FAQ
Questions?
Everything you need to know about Sup AI.